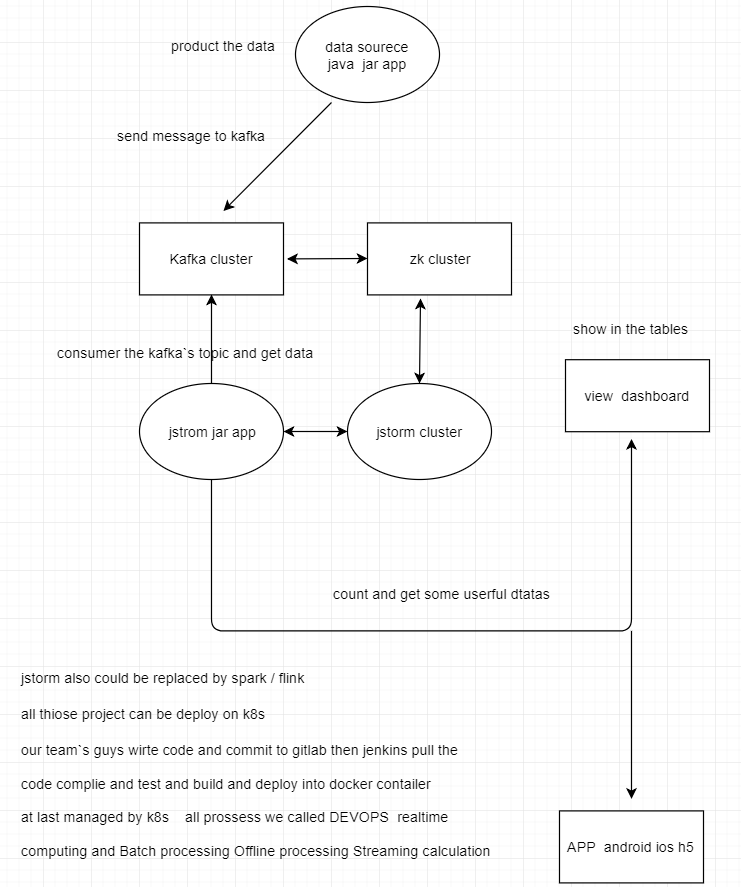
今天元旦假期第一天 在家没有事情 就大致画了下图 关于jstorm kafka zk 集群的图
实验需求: springboot-kafka 生产数据发送kafka集群 springboot-realtime (jstorm应用)消费kafka集群数据并计算处理落地或是可视化展示都可以
三台虚拟机 192.168.108.128 192.168.108.130 192.168.108.131
gitbash/xshell/vm15/IDEA/jdk8/zookeeper/kafka/jstorm/springboot/cnetos7
搭建Linux环境就不这里概述了 2G 内存/每台
linux3台机子的ssh免密登陆也请度娘Google都行
很多资料也请搭建访问官网学习和搭建
为了实验成功呢 所以建议大家先干掉Linux的防火墙机制 免得自己去开放各种端口… 这里关于防火墙的内容大家可以度娘哈
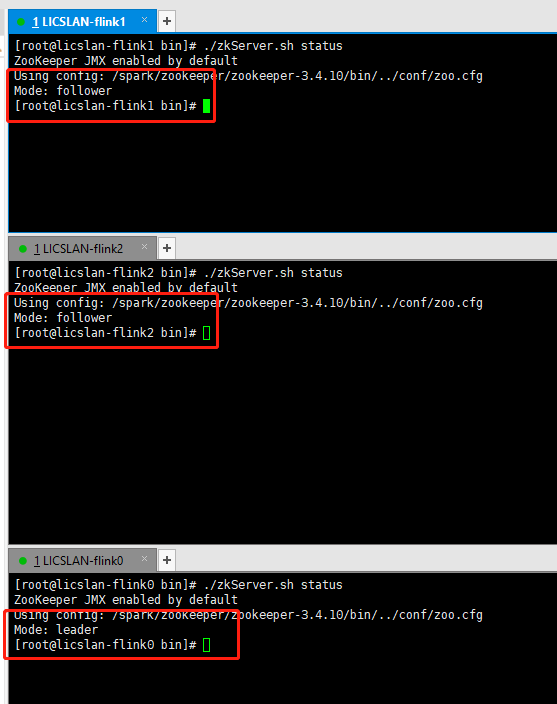
咱们来看看zookeeper 集群搭建和kafka搭建效果吧

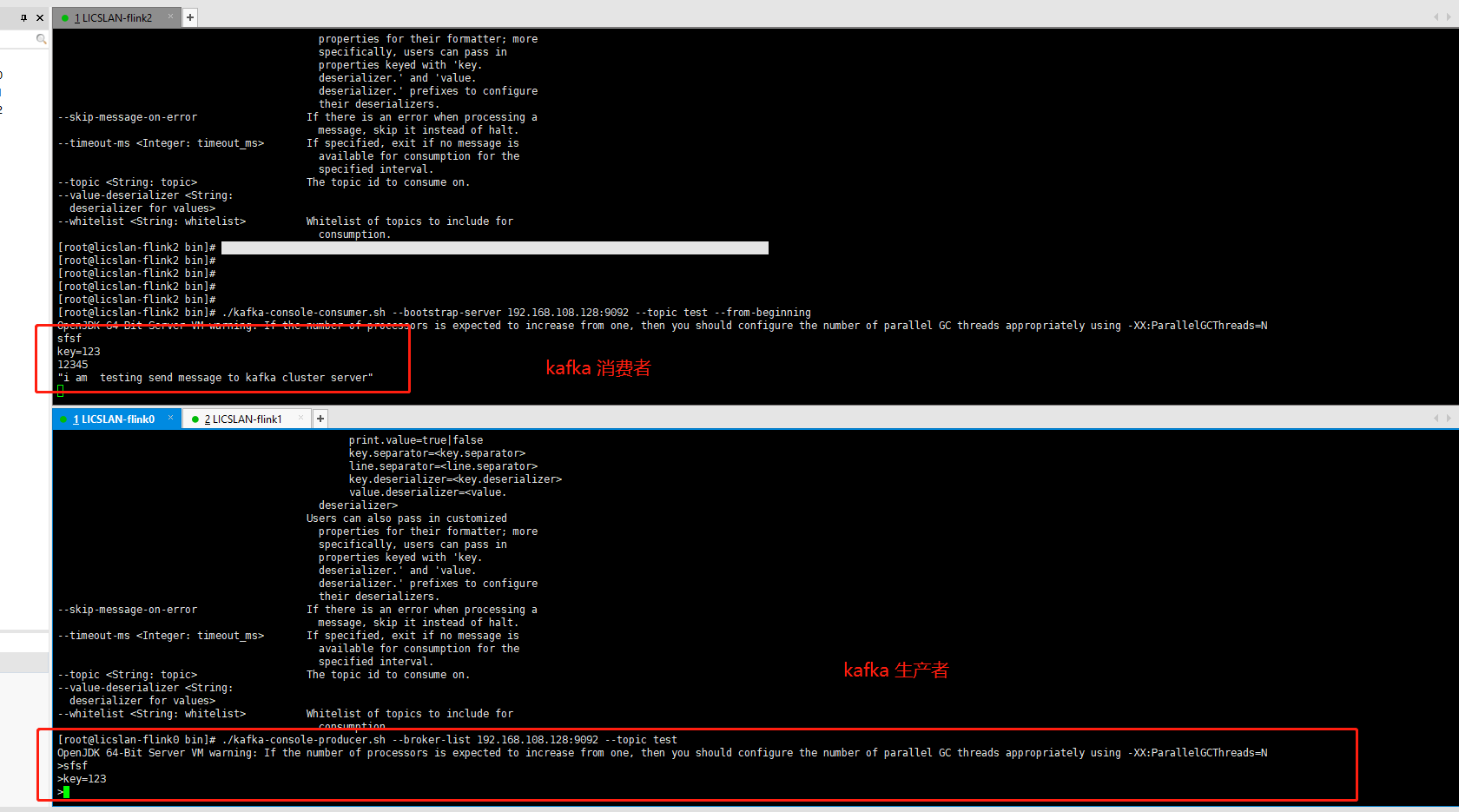
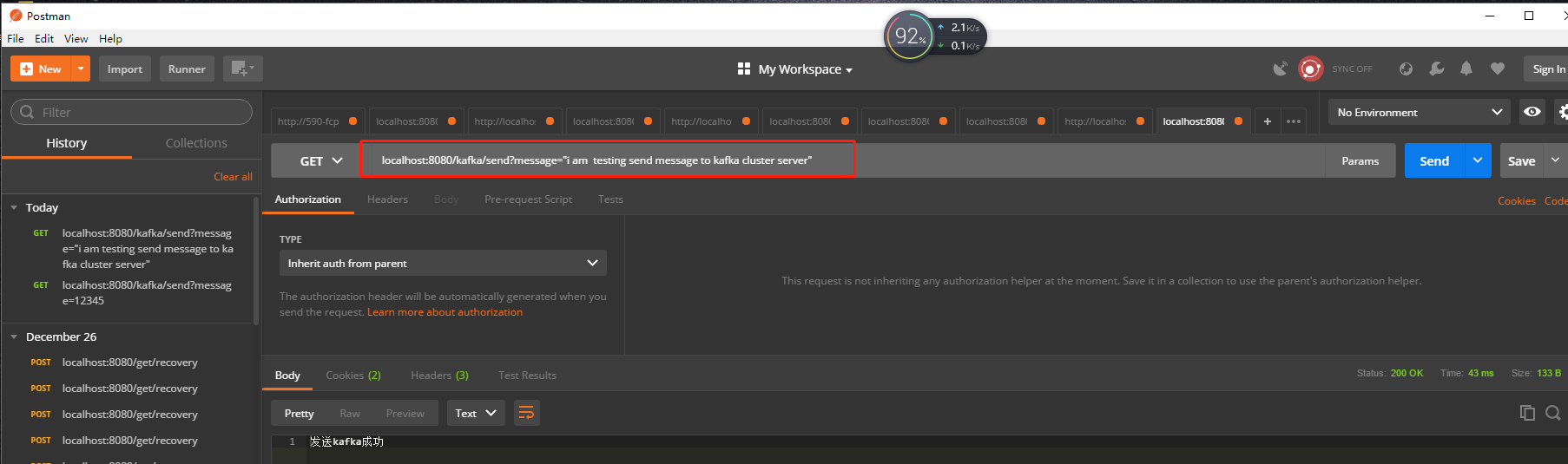
OK 我们来看测试测试效果吧 我们启动kafka集群生产者和消费者 同时搭建了springboot-kafka 发送消费的demo
并使用了postman本地测试本地运行的kafka java程序 来简单生产数据 在Linux环境的服务器也受到了来至本地的Java程序发送的消息
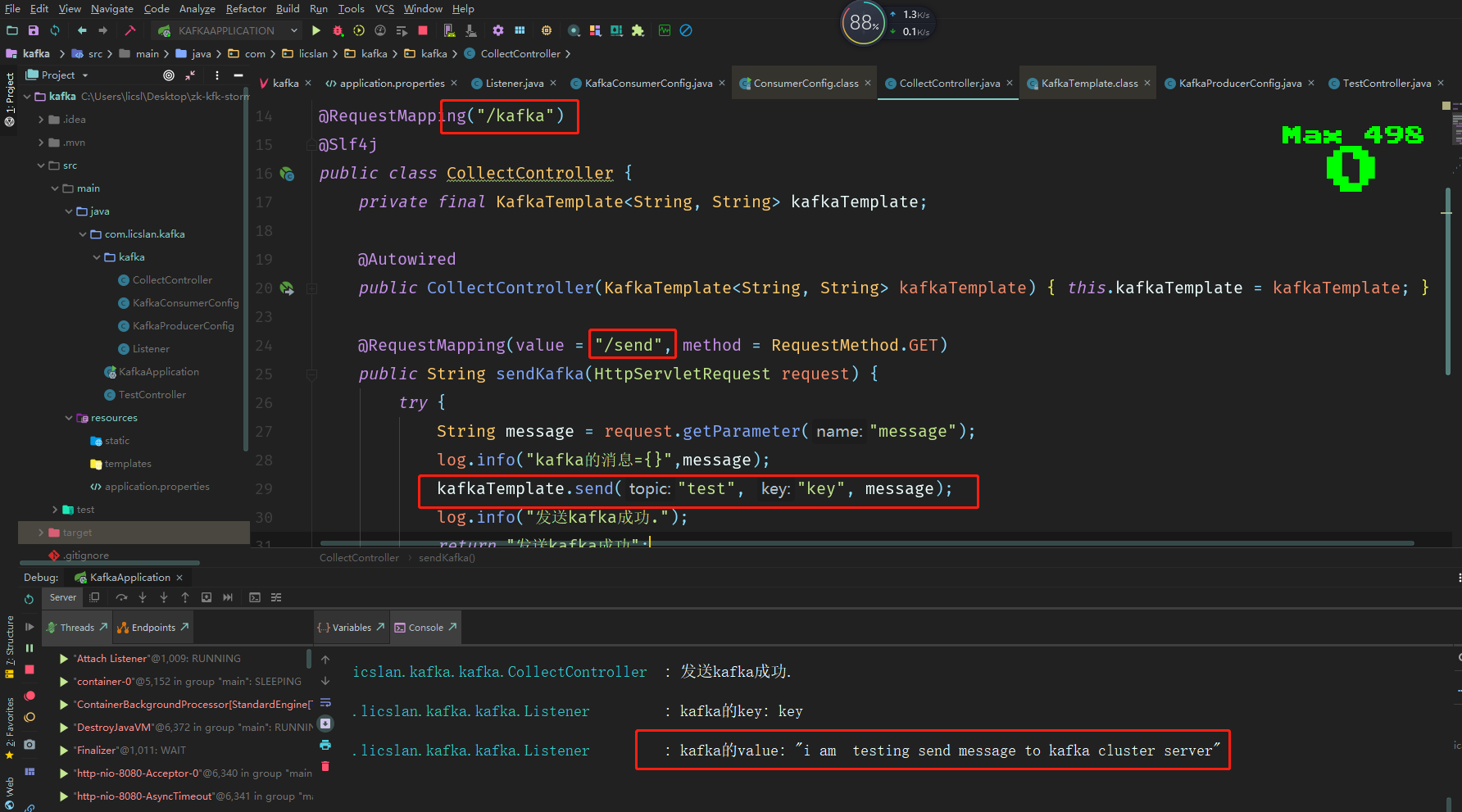
后面也会写着关于jstorm/storm集群的搭建效果和过程
here we go 终于把jstorm 在本地的集群和kafka zookeeper 集群全部搭建完成了 来看一下本地的效果吧
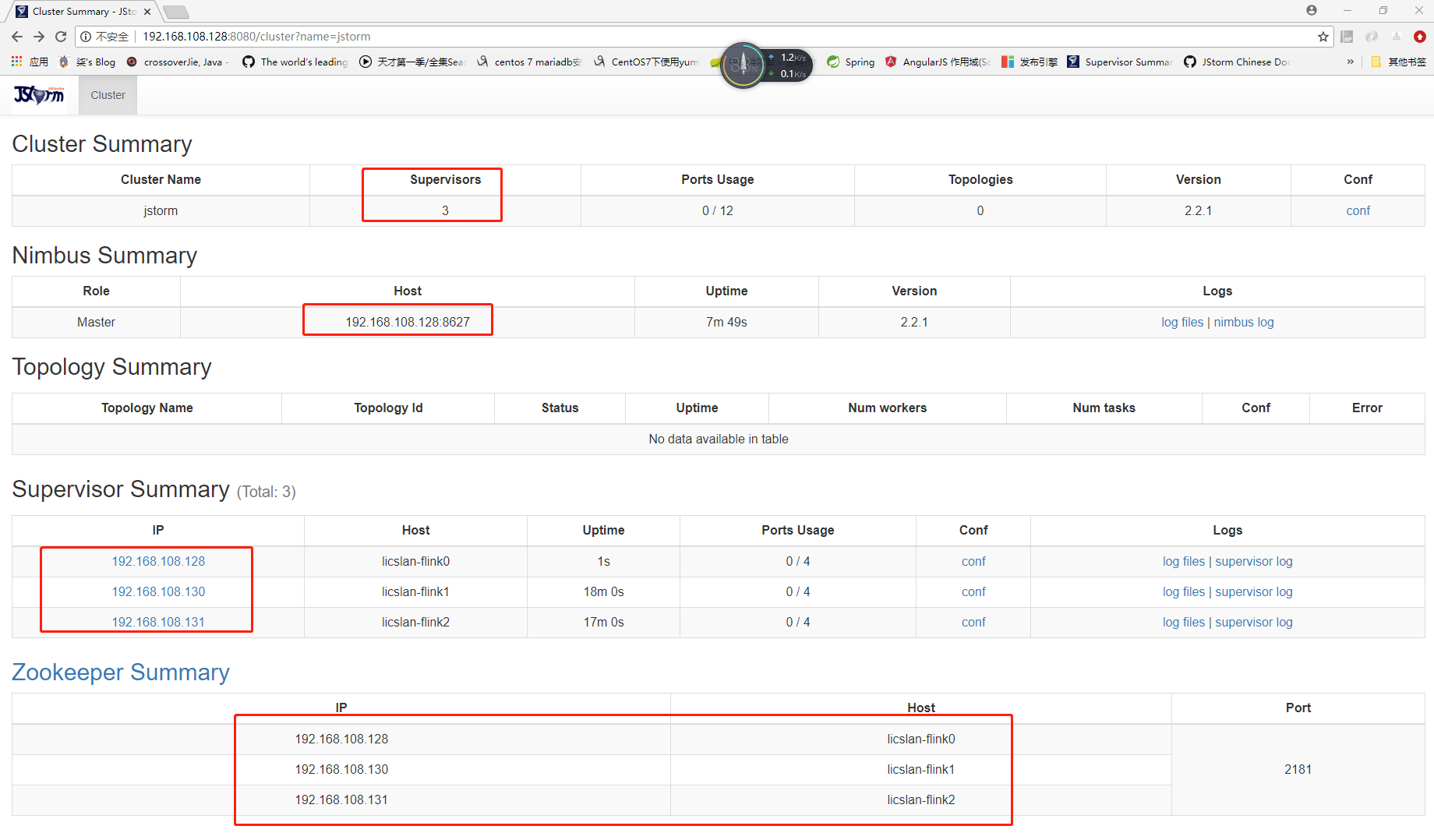
最后我会将整理好的如何搭建zookeeper 和 kafka jstorm 过程写下来…
先来说zookeeper吧
先去官网下载zookeeper Linux的版本 并解压 vim zoo.cfg 主要配置如下图:
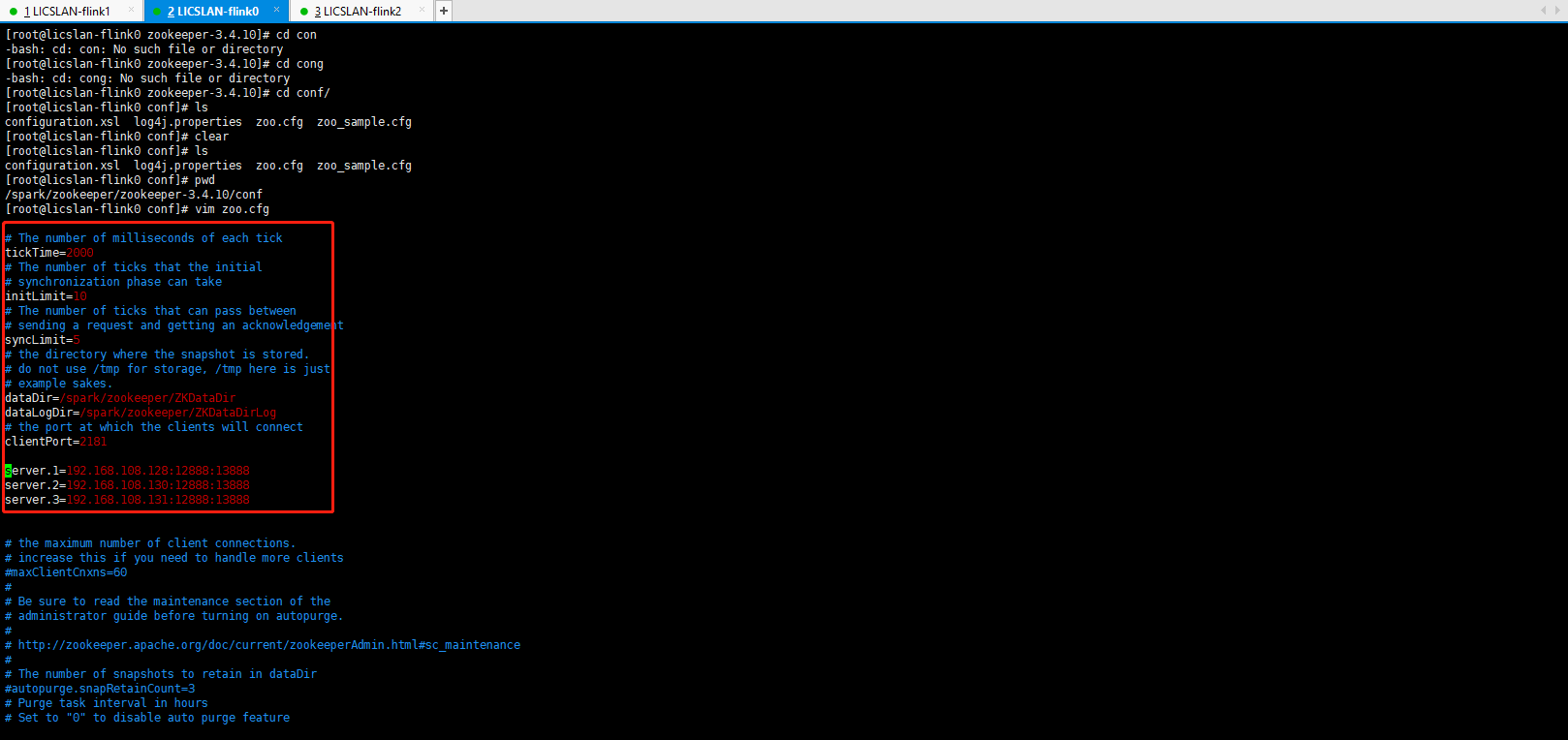
三台机子的配置一样的 配置好了 分别启动就好 ./zkServer.sh start ../conf/zoo.cfg
https://zookeeper.apache.org
再来说kafka吧
先去官网下载kafka Linux的版本 并解压 vim server.propeties 主要配置如下图:
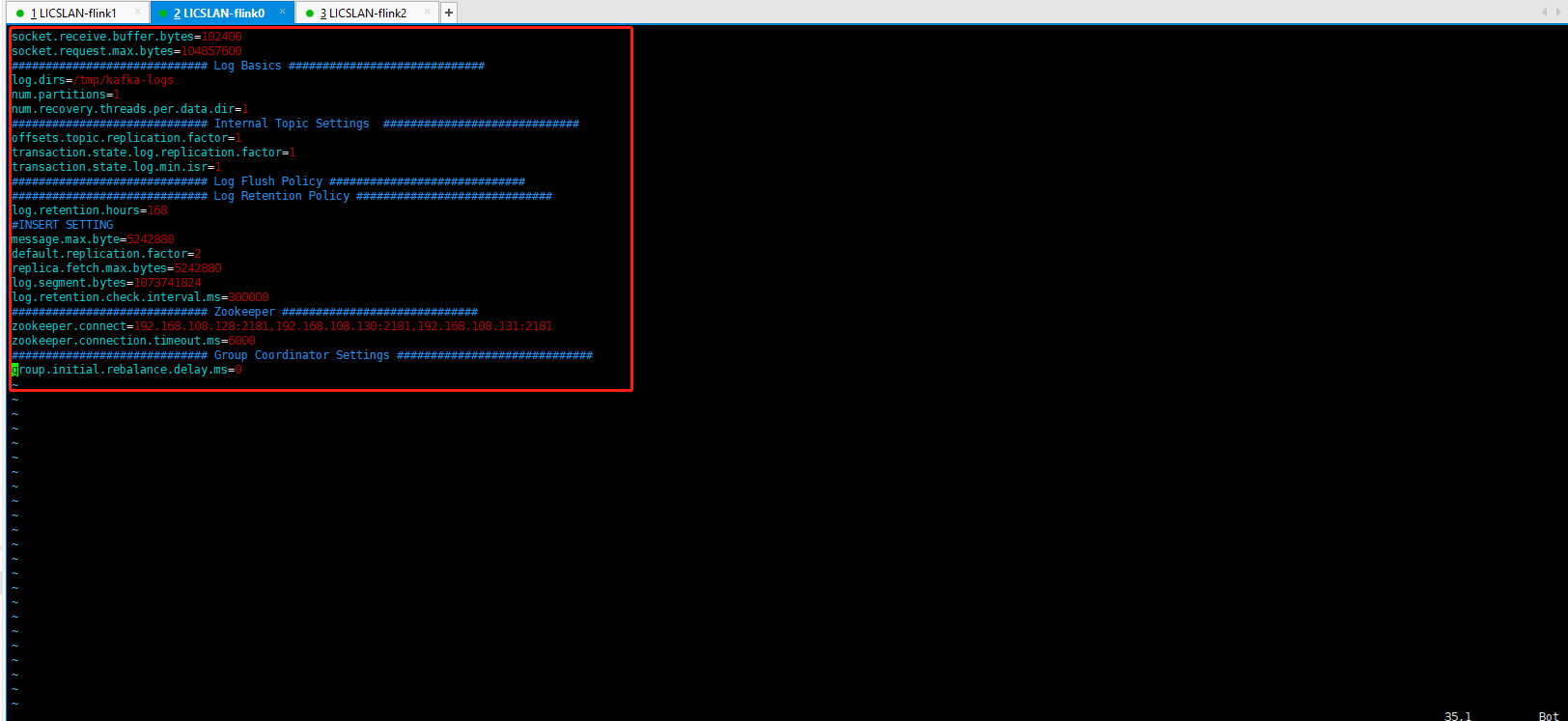
三台机子的配置一样的 配置好了 分别启动就好 kafka 启动 分别创建生产者和消费者 命令请去官网看看 https://kafka.apache.org
最后说jstorm吧
先去官网下载jstorm Linux的版本 并解压 vim storm.yaml 主要配置如下图:
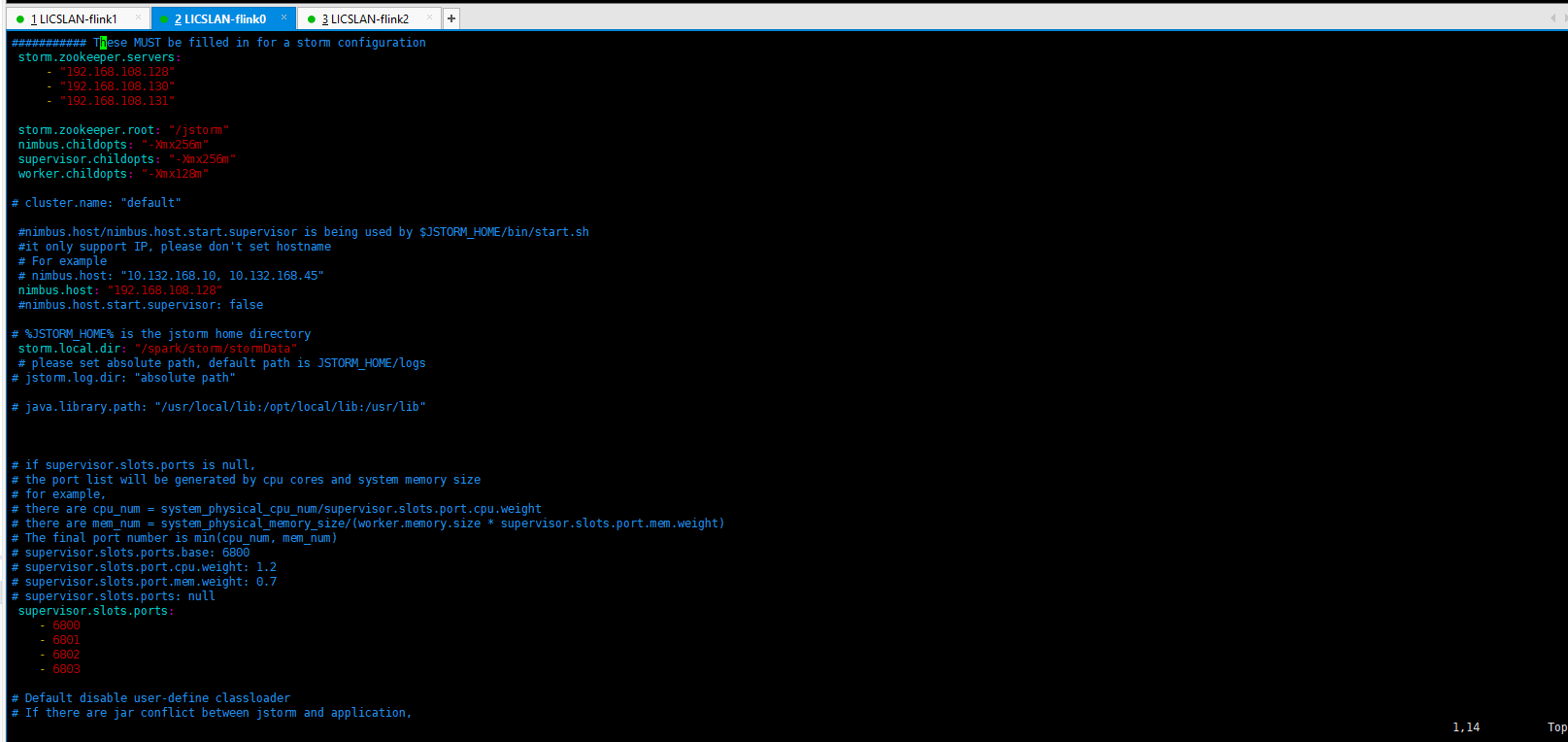
三台机子的配置一样的 配置好了 分别启动就好 jstorm 分别启动nimbus(负责分发代码) supervisor (处理计算任务) https://storm.apache.org
下面是提交到集群的示例 不过中间还是有些错误 日志错误
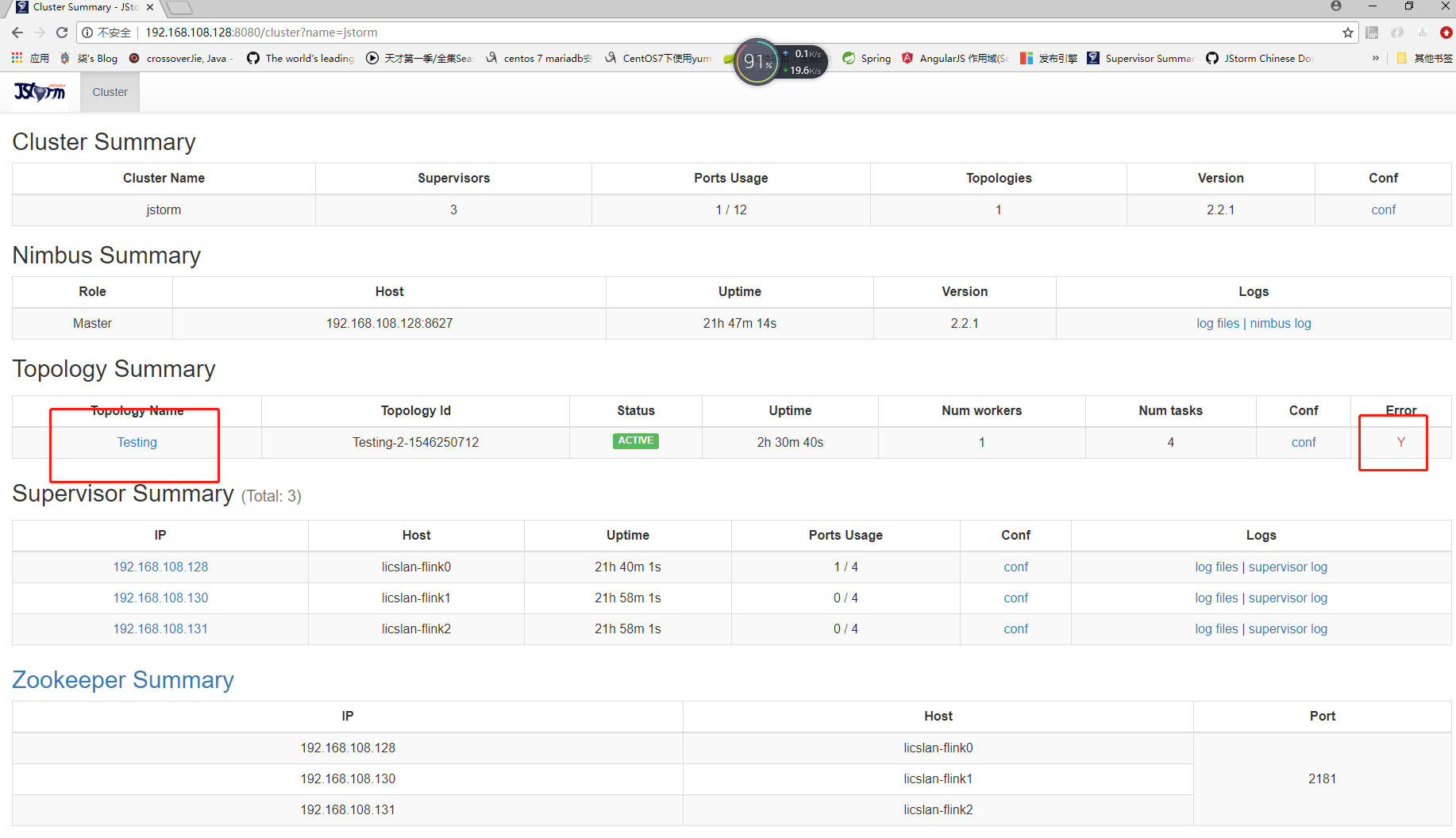
虽说是jstorm 但还是建议看看storm 文档相对完善
思考?
如何讲spring boot kafka storm 整合在一起呢 一般来说 我们是单独的kafka项目 和单独的storm 项目 storm 需要提交到集群
./storm jar xxx.jar xxx.xx.xTopologyMainClass TopologyName
那spring boot启动完了之后加载就会去提交storm到集群 本地整合的时候没有问题 但是提交到集群会有问题的 …
本次项目的架构中可以将jstorm换成spring streaming flink kafka sream 均可 所以实时计算 离线处理 流式处理计算的架构基本大同小异
构建大数据处理平台 以下是我认为需要做的一些步骤吧 一个公司最重要的就是数据和用户了
1.大数据平台需求分析
2.技术预研和比较分析
3.搭建测试环境
4.性能测试调优和保证数据安全/持久化备份
5.编码开发
6.测试验证
7.上线维护
8.迭代升级
再者后面也会建立两个工程关于kafka消息的生产和消费的springboot-kafka项目和jstorm实时计算的项目springboot-realtime
再者后面也写如何mysql/redis/kafka/jstorm/spark/flink调优…. 同时也会带上关于spark/flink机器学习如何利用的小demo 尽请期待